Weather synthesis aims to add weather effects to input videos while preserving scene identity, structure, and
motion. Existing methods lack diversity in weather appearance and effective control over weather dynamics.
Most rely on underspecified text prompts, and general-purpose video editors—optimized for clean,
aesthetic outputs—tend to suppress heavy weather, making dense particle effects difficult to generate.
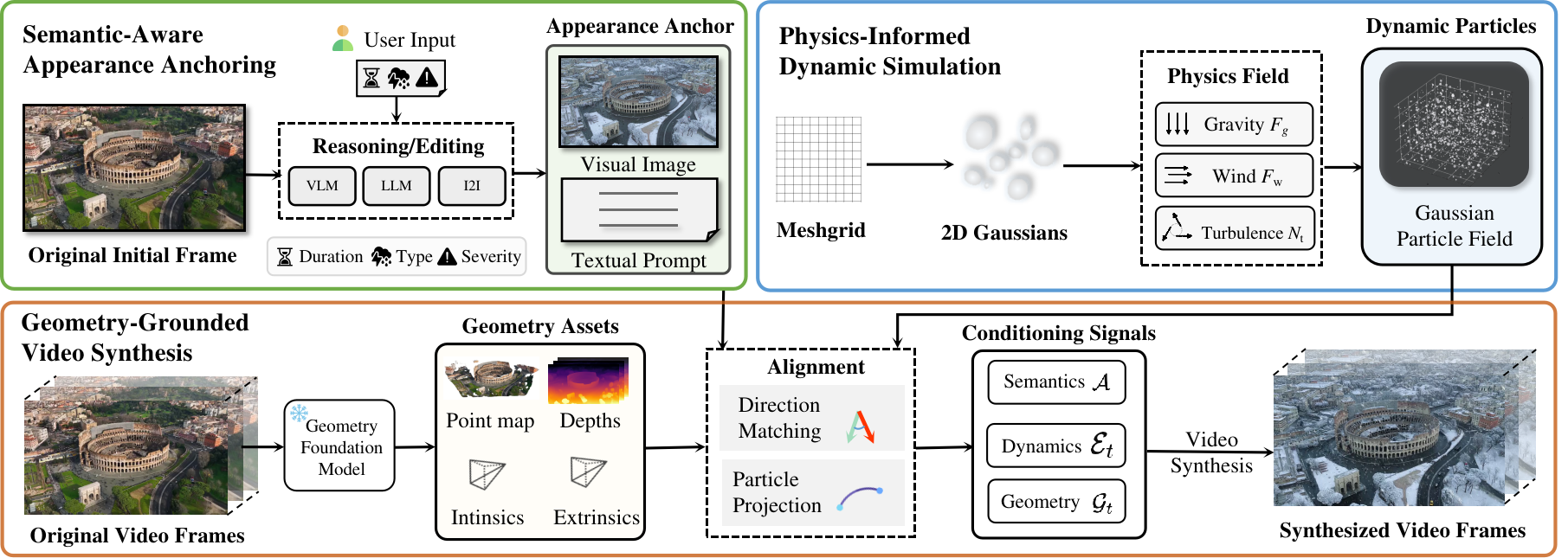
We propose a Semantic-Aware, Physics-Informed, and Geometry-Grounded framework that steers an
off-the-shelf video editor to synthesize diverse global appearances and detailed particle dynamics. We
factorize synthesis into three conditional signals, each a distinct and stable source of guidance:
semantics specifies what the weather should look like, dynamics
governs how it evolves over time, and geometry determines where it should appear in the
scene.
Experiments show our method produces diverse, physically and visually realistic weather effects. Moreover, our
synthesized data significantly improves the robustness of autonomous-driving semantic segmentation under adverse
weather.
Keywords: Weather Synthesis · Video Editing · Particle Simulation